
Entire Code is also available on GITHUB.
Now that we have already coded to get core stock data of companies listed with NASDAQ, it’s time to get some more data from NSE(National Stock Exchange, India).
Python is my ideal choice for the same. I am using Python 3.x to code the script.
As I did not find any reliable free API in my google searches to extract the data of NSE, I am going to get it on my own using web scraping. According to Wikipedia,
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser.
Going on to NSE’s website, I check the webpage of Infosys Live Quote. In there, I have the following details.
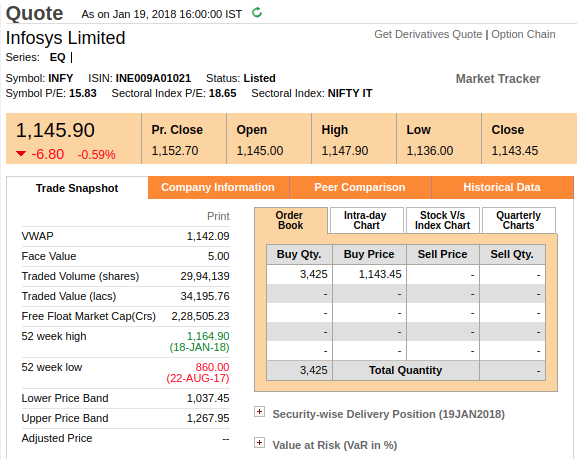
I want the timestamp written next to “Quote”, as well as the other important data. I am going to go and simply inspect the HTML. I simply search “Infosys” in the HTML and get the entire data’s view. The data is in JSON format which is lovely since json.loads is going to make the work easy for me. The data is wrapped under this HTML tag:
div id=”responseDiv” style=”display: none;”
. I just have to get to this tag.
Now that I have analyzed the data, I am going to dive into the favourite part, coding!
import urllib.request def import_web(ticker): """ :param ticker: Takes the company ticker :return: Returns the HTML of the page """ url = 'https://www.nseindia.com/live_market/dynaContent/live_watch/get_quote/GetQuote.jsp?symbol='+ticker+'&illiquid=0&smeFlag=0&itpFlag=0' req = urllib.request.Request(url, headers={'User-Agent' : "Chrome Browser"}) fp = urllib.request.urlopen(req, timeout=10) mybytes = fp.read() mystr = mybytes.decode("utf8") fp.close() return mystr
Let’s first define a function to get the entire HTML of the page. It’s going to take a parameter ticker, eg. INFY for Infosys. Let’s define a variable ‘url’ which takes in the ticker and creates the final string, ‘url’ which we generally open to see the prices. Next, we create a request with the’url’ and the headers.
Headers are often used to “spoof” the User-Agent header value, which is used by a browser to identify itself – some HTTP servers only allow requests coming from common browsers as opposed to scripts.
Let’s open the URL using urllib.request.urlopen method. I am including the request ‘req’ as a parameter and timeout in seconds. Timeout is a very useful method if the internet connection fluctuates. While trying this method on the local system, I am introducing timeout so if the connection breaks in between, after trying for 10 seconds, it stops trying and continue executing the rest of my program.
From the ‘fp’ object, I am reading the data and decoding it to ‘UTF-8’ format as a string. Then am closing the object ‘fp’ and returning the string having the HTML.
def filter_data(string_html): searchString = 'div id="responseDiv" style="display:none"' #assign: stores html tag to find where data starts searchString2 = '/div' #stores: stores html tag where data end sta = string_html.find(searchString) # returns & store: find() method returns the lowest index of the substring (if found). If not found, it returns -1. data = string_html[sta + 43:] #returns & stores: skips 43 characters and stores the index of substring end = data.find(searchString2) # returns & store: find() method returns the lowest index of the substring (if found). If not found, it returns -1. fdata = data[:end] #fetch: stores the fetched data into fdata stripped = fdata.strip() #removes: blank spaces return stripped
The next function filter_data is going to get us the excerpt of the string which contains the dictionary. First, I am defining the HTML tags between which my data lies as searchString and the searchString2. ‘sta’ gets the location of where this string starts. Adding 43 to this value makes me pass this tag as it’s approximately that long. I store the substring of it from this location. The end gets the location of where the end tag string starts. I further take the substring of the data and stores it in fdata. ‘strip’ method removes the whitespaces and then it returns the stripped data.
def get_quote(ticker): """ :param ticker: Takes the company ticker :return: None """ ticker = ticker.upper() try: """fetches a UTF-8-encoded web page, and extract some text from the HTML""" string_html = import_web(ticker) get_data(filter_data(string_html),ticker) except Exception as e: print(e)
Next, let’s process the HTML string further. I am defining a function get_quote which takes in ticker as the parameter. It first converts the ticker to upper. So, ‘infy’ gets converted to ‘INFY’. It first imports the HTML using import_web method. I also need to put a try-catch/except since it can send me an exception because of the timeout in import_web method.
It then calls on the filter_data method on the same HTML string to get the stripped string and passes it on to get_data method. Next, let’s define a method which gets us the data.
import json data_infy = {} data_tcs = {} def get_data(stripped, company): js = json.loads(stripped) datajs = js['data'][0] subdictionary = {} subdictionary['1. open'] = datajs['open'] subdictionary['2. high'] = datajs['dayHigh'] subdictionary['3. low'] = datajs['dayLow'] subdictionary['4. close'] = datajs['lastPrice'] subdictionary['5. volume'] = datajs['totalTradedVolume'] if company == 'INFY': print ( 'Adding value at : ', js['lastUpdateTime'], ' to ', company, ' Price:', datajs["lastPrice"], ) data_infy[js['lastUpdateTime']] = subdictionary elif company == 'TCS': print ( 'Adding value at : ', js['lastUpdateTime'], ' to ', company, ' Price:', datajs["lastPrice"], ) data_tcs[js['lastUpdateTime']] = subdictionary
I have created two dictionaries where we can store the data we get. I am loading the string that I receive as a dictionary using json.loads method. And then, I am just collecting the data I require out of it and storing it in the dictionaries I made w.r.t. the company/ticker.
Now that, the basic code is done. I am going to just work around some extra functionalities that would help me to get it running continuously without any disruption.
import time lsave=time.time() def autoSave(): global lsave curr_time = time.time() if(curr_time >= lsave + 300): with open('infy','a+') as f: f.write(str(data_infy)) with open('tcs','a+') as f: f.write(str(data_tcs)) lsave = time.time() combiner() print("AutoSaved at : "+ time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(lsave)))
Let’s create an autosave function which can save my data every now and then if say, electricity goes off, or someone in the lab accidentally turns off my PC. Sometimes, it happens in our labs when people want to charge their mobile phones and no one is sitting on the system. It’s irritating. 😛
First of all, I am saving the current time when this program starts in a variable ‘lsave’ using time.time method. I am getting the lsave variable using the keyword ‘global’. Then I am taking the current time to only check if it has been 300 seconds or 3 minutes before I last saved it. Now, I simply append the new dictionary onto it and update the new lsave time. Then I run the combiner script to combine these dictionaries into one single dictionary.
def combiner(): file_names = ['infy','tcs'] for ticker in file_names: final = {} with open(ticker,'r') as f: data = f.read() data = data.replace("}{","}split{") splittedData = data.split('split') for dictionary in splittedData: tmp = json.loads(dictionary.replace("'",'"')) for key in tmp.keys(): final[key] = tmp[key] newFileName = ticker with open(newFileName,'w') as fw: fw.write(str(final))
The combiner method is iterating over the files and loading all the dictionaries stored in the file. It is then loading the data in another local dictionary to remove redundancy since dictionaries only have unique keys, in this case, timestamp and then after getting a final combined dictionary, it is then writing it onto the file.
def main(): t_list=['TCS','INFY'] try: while(True): for ticker in t_list: print("Starting get_quote for ",ticker) get_quote(ticker) autoSave() print("Taking a nap! Good Night") time.sleep(30) print("\n\n") except Exception as e: print(e) finally: with open('infy','a+') as f: f.write(str(data_infy)) with open('tcs','a+') as f: f.write(str(data_tcs)) combiner() main()
Now, I am just defining a main method which has a ticker list, the companies for which I need the data. It continously calls on get_quote method to get the quote and add it to the dictionary where our entire data is being stored.
It then calls autoSave method which checks if it has been 5 minutes since the last save and saves the data accordingly. There’s time.sleep(30) to make the program take rest for 30 seconds so it just goes onto NSE website a maximum of twice per minute. I have added a try-catch/except-finally block so if there’s any exception then the data is stored onto our files anyway which would be combined and sorted the next time we open this application.
NOTE: I am writing it this way and using combiner because we had developed a script to collect data at an early stage which wasn’t coded properly. We just extended the script and edited it. This script can be made much better. See our NASDAQ code to see the better way of saving dictionaries. 🙂
Moreover, BeautifulSoup library can also be used to get the required data out of the HTML. I was unaware of it when I wrote the script initially.
Moreover, as this script is parsing the website to get the prices, it must be run during market timings. It is advisable to use a cloud service to deploy this script on so we get the data uninterruptedly. We recommend our trusted cloud services partner, CloudSigma for the same.
Full Code: GitHub
References:
https://docs.python.org/3/library/urllib.request.html
nseindia.com
Wikipedia.org


Thank you for this post !! Quite interesting
What would need to be updated in this code for getting option chain data. Do you have a code for the same….
LikeLike
No, we didn’t explore that part.
LikeLike
Nice Article, but i am getting read operation time out every time, my internet is working fine.
LikeLike
Try to ping the website and check.
ping
LikeLike
The read operation timed out
Taking a nap! Good Night
LikeLike
As this is quite an old experiment, you might want to explore the reason it timed out and probably introduce a fix 🙂
If you need help, do let me know
LikeLike